analysis
NBA W/L Prediction

Introduction
2017-2018 NBA season has been started for three months (Oct to Dec), and I conduct a nba win/loss prediction for the whole rest of the games based on the games that had played.
Analysis
Data Source is based on Baseketball References. During this prediction analysis, I will use Team Per Game Stats, Opponent Per Game Stats, and Miscellaneous Stats, and take data in these three csv as my prediction features. The final result will give the probabilities of a team winning instead of providing absolute “W/L” result.
The result will based on the performance that had played and Elo Score each team obtained.
The Elo rating system is a method for calculating the relative skill levels of team in competitor-versus-competitor games, and it firstly used in chess.
The intuitive understanding of Elo Score is assuming levels that team A and B perform in is and , then the expectation of A wins B is
the expectation of B wins A is
If the true scoring is different from , then the level score would be adjusted by
and will be given accordingly
Requirement
Python 3.6- module
numpy - module
pandas - module
sklearn
Output
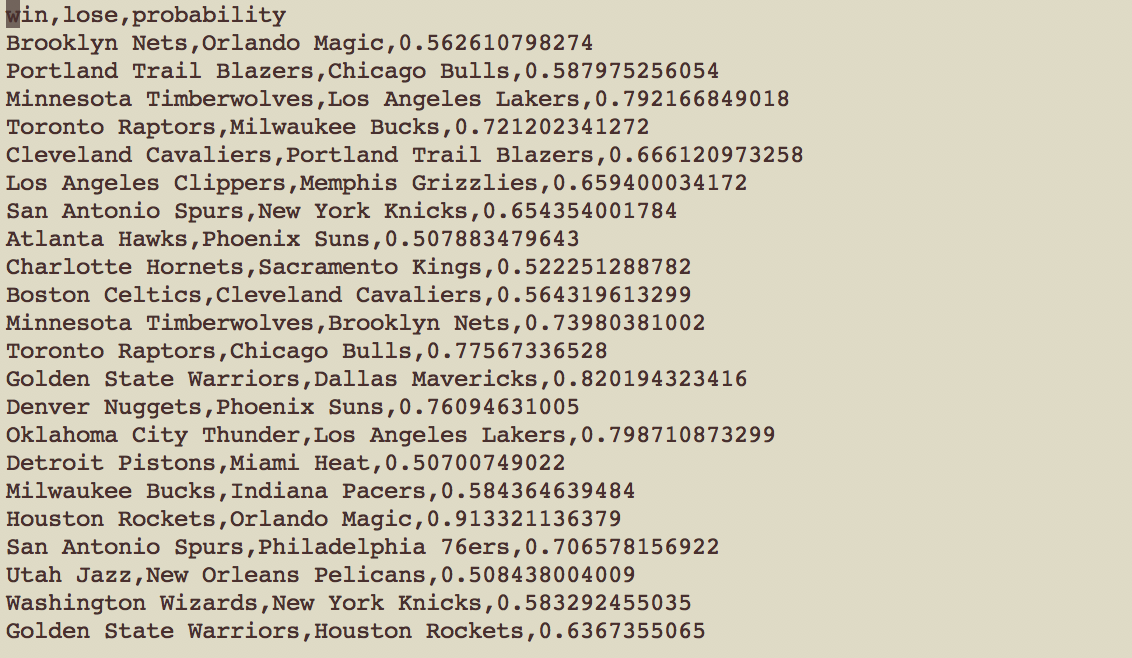
Input
17-18schedule.csv17-18Miscellaneous_Stat.csv2017-2018result.csv2017-2018Opponent_Per_Game_Stat.csv2017-2018Team_Per_Game.csv
Programming
import modules
import pandas as pd
import math
import csv
import random
import numpy as np
from sklearn.model_selection import cross_val_score
from sklearn.linear_model import LogisticRegression
Elo Rating conduct
def calc_elo(win_team, lose_team):
winner_rank = get_elo(win_team)
loser_rank = get_elo(lose_team)
rank_diff = winner_rank - loser_rank
exp = (rank_diff * -1) / 400
odds = 1 / (1 + math.pow(10, exp))
if winner_rank < 2100:
k = 32
elif winner_rank >= 2100 and winner_rank < 2400:
k = 24
else:
k = 16
new_winner_rank = round(winner_rank + (k * (1 - odds)))
new_rank_diff = new_winner_rank - winner_rank
new_loser_rank = loser_rank - new_rank_diff
return new_winner_rank, new_loser_rank
organize input data
def initialize_data(Mstat, Ostat, Tstat):
new_Mstat = Mstat.drop(['Rk', 'Arena'], axis=1)
new_Ostat = Ostat.drop(['Rk', 'G', 'MP'], axis=1)
new_Tstat = Tstat.drop(['Rk', 'G', 'MP'], axis=1)
team_stats1 = pd.merge(new_Mstat, new_Ostat, how='left', on='Team')
team_stats1 = pd.merge(team_stats1, new_Tstat, how='left', on='Team')
print(team_stats1.info())
return team_stats1.set_index('Team', inplace=False, drop=True)
winner prediction
def predict_winner(team_1, team_2, model):
features = []
features.append(get_elo(team_1))
for key, value in team_stats.loc[team_1].iteritems():
features.append(value)
features.append(get_elo(team_2) + 100)
for key, value in team_stats.loc[team_2].iteritems():
features.append(value)
features = np.nan_to_num(features)
return model.predict_proba([features])
during the predicting process, the logistic regression with 10-fold cross validation will be used
print("Fitting on %d game samples.." % len(X))
model = LogisticRegression()
model.fit(X, y)
print("Doing cross-validation..")
print(cross_val_score(model, X, y, cv = 10, scoring='accuracy', n_jobs=-1).mean())
save result

